Long-term Password Scavenging with Scavenger
by Keramas
Last year when I learned of the Scavenger OSINT Bot created by rndinfosecguy for scraping Pastebin for interesting data dumps, I thought it would be neat to see a long-term data trend on what kind of password data was being dumped to Pastebin on a daily basis by analyzing the data over the course of a year or so.
While this will not be a perfect sample due to some gaps in scraping and also likely imperfect filtering on my part, I believe it is an interesting snapshot based on the capabilities of the earlier Scavenger code (~first release timing). Also to note is that this analysis only reviews raw credentials captured, and does not examine the Wordpress, MySQL, RSA, and other features present within Scavenger.
I tried to be as verbose as possible with output just to give others a good idea and starting point if anyone wants to follow suit and do some research of their own. So with all that said, let’s get to the data…
About the Sample Data
From August 2019 to July 1 2020, with a gap from November 2019 through February 2020 (due to some circumstances and then forgetting to redeploy it), Scavenger was run 24/7.
For a duration of roughly 7 months, a total of 17,784 successful password scrapes were performed, each time generating a unique file. The data size of all of these files was approximately 425 MB.
Data Filtering
As all of the discovered dumps are in random formats and in non-standardized formats overall, a series of filtering had to be done to extract the key data (credentials). While some files had only a pair of credentials on each line, there were others that required a lot more to extract cleanly, and this was done as a best effort with regexes.
First, for all of the files, a dirty regex to filter on email addresses was used with egrep to extract and tally those lines up.
[11:32:28]─[keramas@utsusemi]─[~/Downloads/scavenger_data/files_with_passwords]$ cat * | egrep -i ".{1,}@[^.]{1,}" | uniq | wc -l
3230258
In total, there were 3,230,258 lines with email addresses present, but keep in mind that some of these lines were extremely lengthy and contained a varying number of credentials.
Once these lines were exported into a file, a Python script was used to perform further filtering with more dirty regexes.
import re
import sys
import os
import csv
import argparse
from datetime import datetime
def get_args():
parser = argparse.ArgumentParser(description="",epilog="")
parser.add_argument('-f','--file',type=str, help="data file", required=True)
args = parser.parse_args()
file = args.file
return file
def filter(line):
line = line.strip()
# Check for presence of at least one email address
if re.search(r".{1,}@[^.]{1,}",line):
# If true, find the easy to parse data that is just a single email address + password on one line
if re.search(r"\s?(.{1,}@[^.]{1,}.{1,10})(:|;|,)([^\s]+)",line):
try:
data = re.search(r"(.{1,}\s)?(.{1,}@[^.]{1,}.{1,10})(:|;|,)([^\s]+)",line)
if data.group(2) != None and data.group(4) != None:
username = data.group(2)
password = data.group(4)
catalog(username,password)
else:
return
except:
return
# Move on to lines that have more data and multiple credential sets
else:
# Break apart the lines by spaces for better parsing
split_lines = line.split(" ")
for i in split_lines:
# Get basic auth from URLs
if re.search(r"(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:'\".,<>?«»“”‘’]))",i):
try:
basic_auth = re.search(r"(\/\/)(.{1,})(:)(.{1,})(@)",i)
if data.group(2) != None and data.group(4) != None:
username = basic_auth.group(2)
password = basic_auth.group(4)
catalog(username,password)
else:
return
except:
return
else:
try:
data = re.search(r"(.{1,}\s)(.{1,}@[^.]{1,}.{1,10})(:|;|,)([^\s]+)",i)
if data.group(2) != None and data.group(4) !=None:
username = data.group(2)
password = data.group(4).strip("|")
password = password.strip("|Premium")
catalog(username,password)
else:
return
except:
return
else:
return
def catalog(username,password):
# Take data from the filtering and populate the dictionary/export data to csv file
with open('pastebin_dumps.csv', mode='a+') as dump_csv:
dump_writer = csv.writer(dump_csv, delimiter=",", quotechar='"', quoting=csv.QUOTE_MINIMAL)
dump_writer.writerow([username,password])
dump_csv.close()
def main():
startTime = datetime.now()
print("[!] Parsing data file...")
print("[>] Start time - %s" % str(startTime))
datafile = get_args()
with open(datafile,'r') as data_dump:
for line in data_dump:
filter(line)
finishTime = datetime.now()
print("[!] Finished @ %s - Total time: %s" % (str(finishTime),str(finishTime - startTime))
if __name__ == "__main__":
main()
[16:52:19]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ python3 datafilter.py -f emailfilterpass1.txt
[+] Parsing data file...
[>] Start time - 2020-07-19 16:55:02.250007
[!] Finished - 0:04:29.752115
Once again, this is very likely far from perfect filtering nor is it optimized by any means, and it has most definitely missed some entries in the overall data. However, it gets close to cleaning everything up for the most part. The results are the following:
[17:46:32]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ wc -l pastebin_dumps.csv
2974111 pastebin_dumps.csv
[17:46:43]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ uniq pastebin_dumps.csv | wc -l
2970079
Approximately 2,970,079 lines of pure credentials. It is important to note that a good portion of this can be attributed to just randomly generated test credentials and other throw-away looking credentials that are not from humans.
Extracting out just the passwords present in those lines, there are a total of 2,941,857
[18:03:21]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ wc -l pwonly.txt
2974111 pwonly.txt
[18:03:24]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ uniq pwonly.txt | wc -l
2941857
Data Analysis
Frequency of Dumps Discovered
Scavenger includes a tally feature in the statistics directory which adds a byte to a file for the day a successful scrape occurred. Based on the discovery algorithms of Scavenger and the statistics data, the following are graphs that snapshot the frequency of dumps discovered per day on Pastebin.
Daily dump discovery
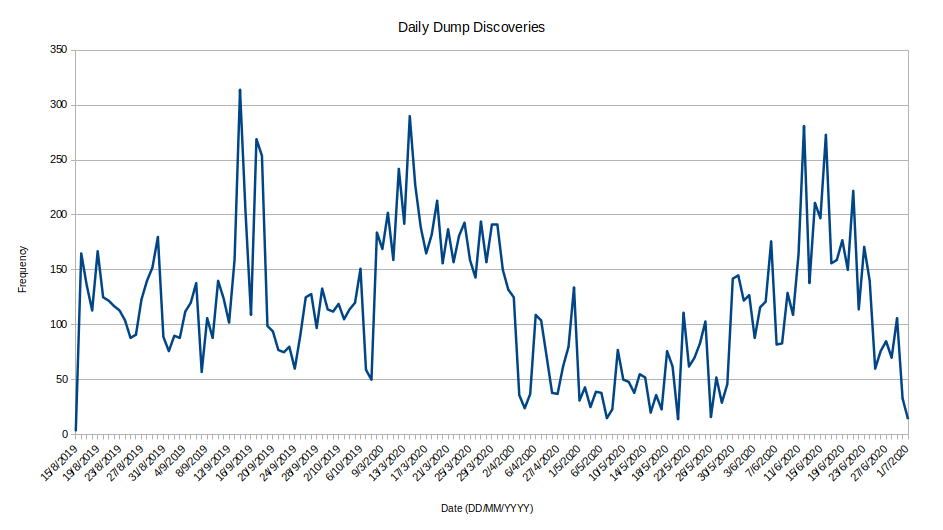
September 14, 2019 saw the highest daily dump rate at 314 dumps, while May 20, 2020 was the lowest daily rate at 14 dumps.
Monthly dump discovery
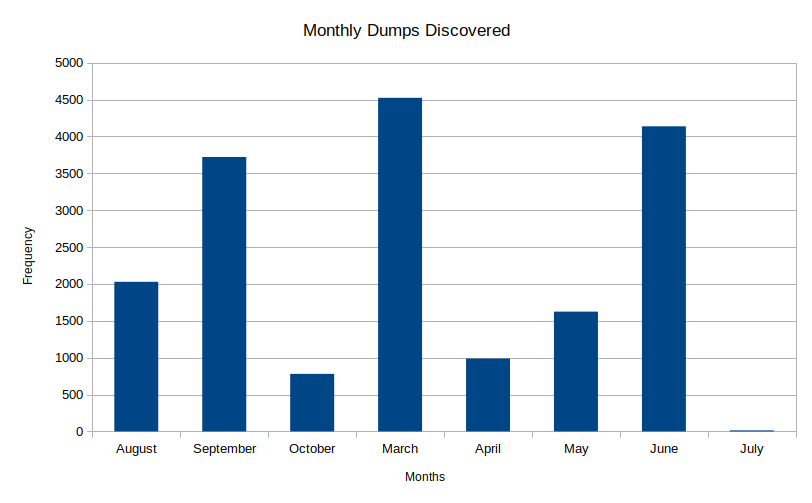
Overall in terms of dumps per month, March 2020 took the cake with a total of 4523 dumps. Perhaps people were starting to get bored at the beginning of all the quarantine and isolation due to Covid-19?
Password Analysis
Pipal was used to perform a standard password analysis against the nearly 3 million passwords.
The following is the result:
[18:02:30]─[keramas@utsusemi]─[~/Documents/pipal]$ ruby pipal.rb ../scavenger_data/pwonly.txt
Generating stats, hit CTRL-C to finish early and dump stats on words already processed.
Please wait...
Processing: 100% |ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo| Time: 00:01:47
Basic Results
Total entries = 2974104
Total unique entries = 1138215
Top 10 passwords
123456 = 5546 (0.19%)
SamplePass$$99 = 3861 (0.13%)
a123456789 = 3206 (0.11%)
123456789 = 2451 (0.08%)
password = 1279 (0.04%)
19SAM = 1271 (0.04%)
00 = 1125 (0.04%)
j38ifUbn = 1013 (0.03%)
qwerty = 964 (0.03%)
prueba = 959 (0.03%)
Top 10 base words
password = 5530 (0.19%)
samplepass = 3861 (0.13%)
roblox = 3407 (0.11%)
qwerty = 3394 (0.11%)
soccer = 2904 (0.1%)
pokemon = 2475 (0.08%)
football = 2323 (0.08%)
charlie = 2260 (0.08%)
jordan = 2252 (0.08%)
alex = 2230 (0.07%)
Password length (length ordered)
1 = 800 (0.03%)
2 = 9666 (0.33%)
3 = 2283 (0.08%)
4 = 33682 (1.13%)
5 = 35939 (1.21%)
6 = 255935 (8.61%)
7 = 181665 (6.11%)
8 = 916931 (30.83%)
9 = 545526 (18.34%)
10 = 417440 (14.04%)
11 = 209259 (7.04%)
12 = 131024 (4.41%)
13 = 65054 (2.19%)
14 = 43452 (1.46%)
15 = 24311 (0.82%)
16 = 21194 (0.71%)
17 = 9048 (0.3%)
18 = 6886 (0.23%)
19 = 6824 (0.23%)
20 = 5704 (0.19%)
21 = 3488 (0.12%)
22 = 2481 (0.08%)
23 = 2034 (0.07%)
24 = 1264 (0.04%)
25 = 1131 (0.04%)
One to six characters = 338305 (11.38%)
One to eight characters = 1436901 (48.31%)
More than eight characters = 1537203 (51.69%)
Only lowercase alpha = 408594 (13.74%)
Only uppercase alpha = 5474 (0.18%)
Only alpha = 414068 (13.92%)
Only numeric = 199277 (6.7%)
First capital last symbol = 46853 (1.58%)
First capital last number = 628690 (21.14%)
Single digit on the end = 362609 (12.19%)
Two digits on the end = 595863 (20.04%)
Three digits on the end = 295531 (9.94%)
Character sets
loweralphanum: 1334504 (44.87%)
mixedalphanum: 710515 (23.89%)
loweralpha: 408594 (13.74%)
numeric: 199277 (6.7%)
mixedalphaspecialnum: 100298 (3.37%)
loweralphaspecialnum: 50728 (1.71%)
mixedalpha: 48424 (1.63%)
upperalphanum: 22534 (0.76%)
loweralphaspecial: 13508 (0.45%)
mixedalphaspecial: 10213 (0.34%)
specialnum: 7571 (0.25%)
upperalpha: 5474 (0.18%)
upperalphaspecialnum: 2998 (0.1%)
upperalphaspecial: 321 (0.01%)
special: 265 (0.01%)
Character set ordering
stringdigit: 1647250 (55.39%)
allstring: 462492 (15.55%)
othermask: 344977 (11.6%)
alldigit: 199277 (6.7%)
stringdigitstring: 123952 (4.17%)
digitstring: 116847 (3.93%)
digitstringdigit: 34253 (1.15%)
stringspecialdigit: 26269 (0.88%)
stringspecialstring: 6772 (0.23%)
stringspecial: 5055 (0.17%)
specialstring: 3761 (0.13%)
specialstringspecial: 2934 (0.1%)
allspecial: 265 (0.01%)
What does the above data show? Well, due to a heavy amount of default credentials for what appears to be burner accounts or test account, those end up taking the highest rankings in terms of top passwords and such. However, looking at the top base words used for passwords, that paints a slightly different picture as to what is used most commonly before mutating or adding other special characters/numbers.
To get a different view of data, I eliminated all instances of the top 10 passwords listed above. After removing these, there are still 2,753,297 passwords left, and when filtered down, 1,069,622 unique passwords. Redoing Pipal, the following results are attained:
Basic Results
Total entries = 2775061
Total unique entries = 1069622
Top 10 passwords
12345 = 897 (0.03%)
252) = 849 (0.03%)
164) = 849 (0.03%)
charlie1 = 758 (0.03%)
YAgjecc826 = 676 (0.02%)
nutmeg123 = 643 (0.02%)
reynalds88 = 640 (0.02%)
Missing123 = 638 (0.02%)
1j2o3a4o = 636 (0.02%)
pesado123 = 636 (0.02%)
Top 10 base words
roblox = 3251 (0.12%)
soccer = 2794 (0.1%)
pokemon = 2325 (0.08%)
football = 2265 (0.08%)
jordan = 2188 (0.08%)
charlie = 2186 (0.08%)
password = 2165 (0.08%)
dragon = 2054 (0.07%)
daniel = 1930 (0.07%)
Password length (length ordered)
1 = 800 (0.03%)
2 = 8541 (0.31%)
3 = 2241 (0.08%)
4 = 32950 (1.19%)
5 = 34081 (1.23%)
6 = 241643 (8.71%)
7 = 176112 (6.35%)
8 = 864507 (31.15%)
9 = 509106 (18.35%)
10 = 384662 (13.86%)
11 = 193569 (6.98%)
12 = 120092 (4.33%)
13 = 59693 (2.15%)
14 = 35659 (1.28%)
15 = 22340 (0.81%)
16 = 19765 (0.71%)
[SNIP]
Again, some weird outliers in the data that take top 10 password spots, but there are still a couple of interesting entries. Additionally, the top 10 base words changed slightly. Based on the above, this means that a good portion of this data is quite unique, and could be useful for password lists utilized for offline hash cracking to see what kind of hits it gets.
Email Domain Analysis
A short analysis of email domain frequency was also performed based on the email addresses present in the dumps.
[12:03:37]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ cat pastebin_dumps.csv | cut -d "," -f 1 | cut -d "@" -f 2 > email_domains_only.txt
After a bit of filtering, Pipal was used again to analyze the top 10 email domains.
Top 10 Email Domains:
gmail.com = 1035171 (34.81%)
hotmail.com = 346788 (11.66%)
yahoo.com = 280011 (9.42%)
t-online.de = 78169 (2.63%)
arcor.de = 71354 (2.4%)
aol.com = 56682 (1.91%)
web.de = 37898 (1.27%)
msn.com = 33227 (1.12%)
orange.fr = 31047 (1.04%)
hotmail.co.uk = 30410 (1.02%)
It should be no surprise that Gmail takes the cake here as the highest frequency email domain found in the dump data.
Keywords Present in Scraped Files - Online Services
A majority of the dumps were essentially email + password combinations with no additional information as to what the credentials belonged to; however, there was still a large amount of dumps that indicated what the credentials were for. Using a list of popular online services (maily taken from Wikipedia with some custom additions as well), a Python script was created to count all the times the services were mentioned in each dump and then summed up. Naturally, this is not 100% accurate as certain passwords could contain these words, but it was best effort.
import os
import re
directory = "/home/keramas/Documents/scavenger_data/files_with_passwords/"
data_accumulator = dict()
counter = 1
for dump_file in os.scandir(directory):
with open(dump_file, 'r') as dump:
try:
dumpline = dump.readline()
print(f"Iterating over file {str(dump_file)} #{counter}/17784")
while dumpline:
try:
dumpline = str(dump.readline()).strip('\n')
with open("/home/keramas/Documents/scavenger_data/service_list.txt", 'r') as service_list:
service = service_list.readline()
while service:
service = str(service_list.readline()).strip('\n')
for service in service_list:
count = len(re.findall(service.strip(), dumpline.strip(), re.IGNORECASE))
if service.strip() in data_accumulator:
data_accumulator[service.strip()] += count
else:
data_accumulator[service.strip()] = count
except:
pass
except:
pass
counter += 1
print(data_accumulator)
Based on the returned dictionary output, this was placed through another Python script to generate a word map to illustrate the frequency of the online services.
[16:46:11]─[keramas@utsusemi]─[~/Documents/scavenger_data]$ python3 keywords.py
Iterating over file <DirEntry '8WEs8N5i_pastebincom'> #1/17784
Iterating over file <DirEntry 'NjiXfKdG_pastebincom'> #2/17784
Iterating over file <DirEntry 'DvbLNMDk_pastebincom'> #3/17784
Iterating over file <DirEntry 'CTPyAUFr_pastebincom'> #4/17784
Iterating over file <DirEntry 'b5XFaBMM_pastebincom'> #5/17784
Iterating over file <DirEntry '6biAXZEY_pastebincom'> #6/17784
[SNIP]
Iterating over file <DirEntry 'qr38piad_pastebincom'> #17784/17784
{'Tmall': 150, 'Facebook': 2361, 'Baidu': 26, 'Tencent': 39, 'Sohu': 202, 'Taobao': 84, 'Haosou': 1, 'Yahoo!': 10, 'Jingdong': 0, 'Wikipedia': 276, 'Amazon': 22876, 'Sina': 7778, 'Windows': 6209, 'Reddit': 109, 'Netflix': 16773, 'Zoom': 2023, 'Xinhua': 17, 'Okezone': 2, 'Blogspot': 412, 'Microsoft': 2388, 'VK': 7397, 'CSDN': 15, 'Instagram': 1502, 'Alipay': 29, 'Twitch': 184, 'Bing': 2858, 'Google': 42758, 'BongaCams': 0, 'LiveJasmin': 3, 'Tribun': 78, 'Panda': 4023, 'Twitter': 7430, 'Zhanqi': 1, 'Worldometer': 0, 'Stack': 6158, 'Naver': 3375, 'Tianya': 41, 'AliExpress': 25, 'eBay': 793, 'Mama': 7266, 'Spotify': 94017, 'Riot': 2432, 'battle.net': 443, 'Blizzard': 342, 'Roblox': 18447, 'Origin': 8231, 'Steam': 2178, 'Disney': 16586}
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import pandas as pd
from PIL import Image
data_dict = {'Tmall': 150, 'Facebook': 2361, 'Baidu': 26, 'Tencent': 39, 'Sohu': 202, 'Taobao': 84, 'Haosou': 1, 'Yahoo!': 10, 'Jingdong': 0, 'Wikipedia': 276, 'Amazon': 22876, 'Sina': 7778, 'Windows': 6209, 'Reddit': 109, 'Netflix': 16773, 'Zoom': 2023, 'Xinhua': 17, 'Okezone': 2, 'Blogspot': 412, 'Microsoft': 2388, 'VK': 7397, 'CSDN': 15, 'Instagram': 1502, 'Alipay': 29, 'Twitch': 184, 'Bing': 2858, 'Google': 42758, 'BongaCams': 0, 'LiveJasmin': 3, 'Tribun': 78, 'Panda': 4023, 'Twitter': 7430, 'Zhanqi': 1, 'Worldometer': 0, 'Stack': 6158, 'Naver': 3375, 'Tianya': 41, 'AliExpress': 25, 'eBay': 793, 'Mama': 7266, 'Spotify': 94017, 'Riot': 2432, 'battle.net': 443, 'Blizzard': 342, 'Roblox': 18447, 'Origin': 8231, 'Steam': 2178, 'Disney': 16586}
service_names = ''
stopwords = set(STOPWORDS)
wordcloud = WordCloud(width = 800, height = 800,
background_color ='white',
stopwords = stopwords,
min_font_size = 10).generate_from_frequencies(data_dict)
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()
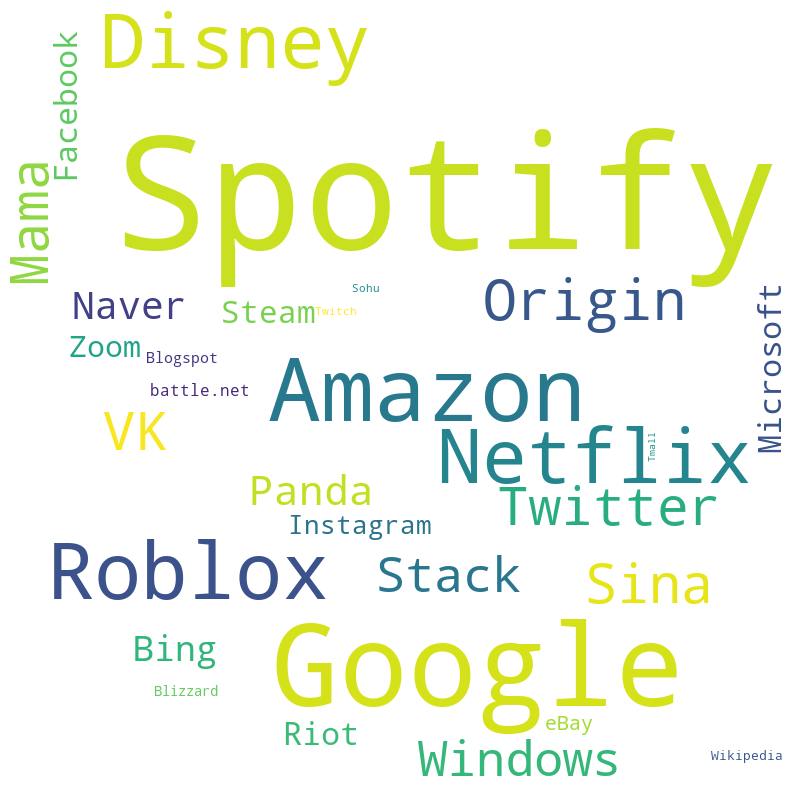
People sure seem to be gunning for that free Spotify this past year!
Conclusion
While I am not a data expert and this is not a perfect sample by any means, it is interesting to see how much ephemeral password dump data is put into Pastebin on a daily basis. In summary, over the course of roughly 7 months or so in total, it was possible to scrape nearly 3 million passwords. It is important to understand, however, that this is based on the functionality of how Scavenger scrapes, so it is very possible that there were way more being dumped. Nonetheless, I think it did a pretty stellar job of discovery overall (and this was using code before improvements were made). Additionally, while some dumps are clearly just test creds or burner accounts, a good portion of the data is indeed legitimite dumps of (potentially) valid credentials from various phishing activity, breaches, or user compromise.
Shoutout and thanks to rndinfosecguy for developing an interesting OSINT tool for data collection and analysis! This yielded a good amount of interesting data metrics and also helped generate a new password cracking wordlist.